



Understanding RLHF
The Technology That Made ChatGPT Chatty
In the last writeup, I traced the evolution of generative AI from the introduction of Transformers through the release of ChatGPT. When mentioning ChatGPT, I touched on how Reinforcement Learning from Human Feedback (RLHF) helped transform powerful but unwieldy language models into helpful assistants. Today, before finishing the brief history of GenAI, I want to dive deeper into this technique, exploring how researchers scaled it effectively and why it proved so transformative. I’ll also detail some of the unique challenges that arose from its implementation, and some interesting ideas that were developed to mitigate them.
The Birth of RLHF: Teaching AI to Write Better Summaries
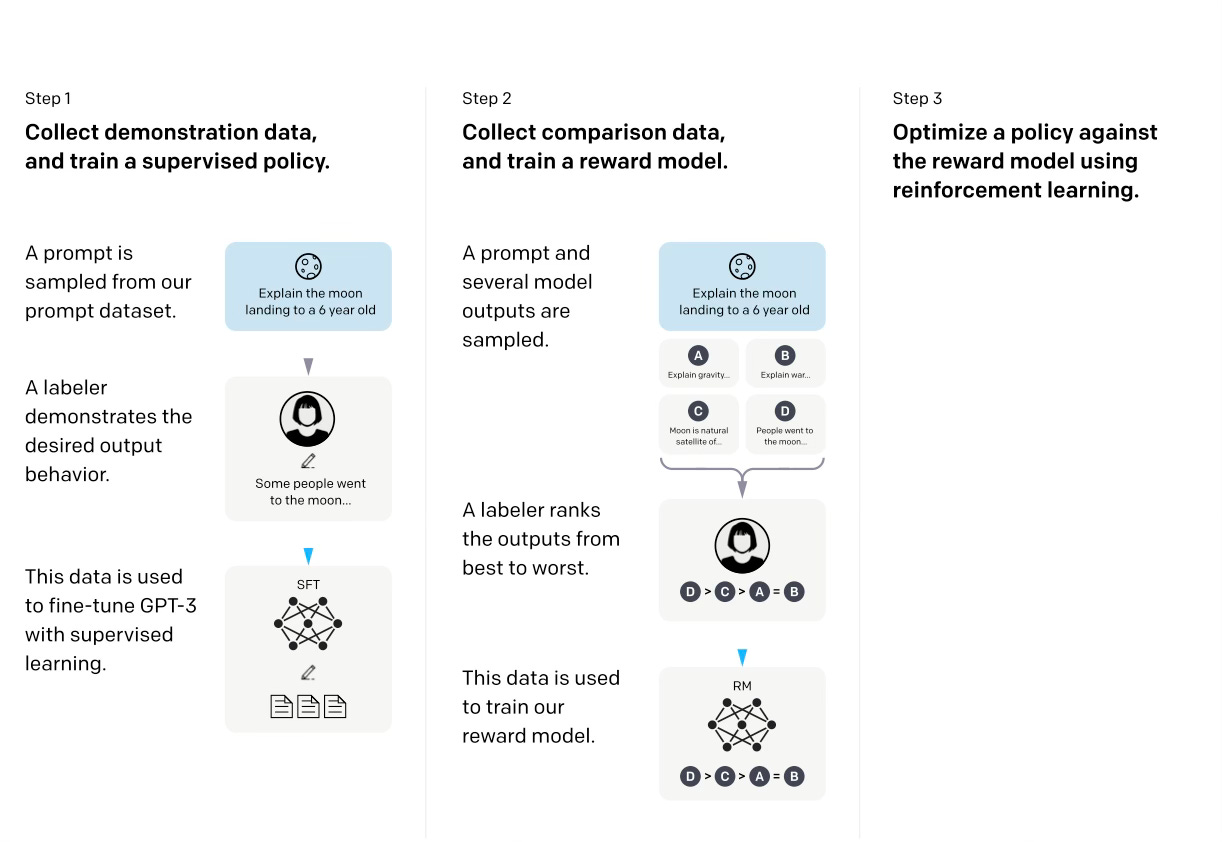
The journey to effective RLHF began with a seemingly simple task: teaching AI to write better summaries. In 2020, researchers at OpenAI published "Learning to Summarize with Human Feedback," demonstrating how human preferences could guide AI behavior. Rather than just showing a model examples of good summaries, they developed a process where human feedback could actively shape the model's outputs. Think of it like teaching someone to cook – instead of just providing recipes, you're tasting their dishes and offering specific guidance on how to improve.

How exactly did they do this? The process began with collecting human preferences on summaries. Rather than asking humans to write "perfect" summaries (which would be time-consuming and potentially inconsistent), they showed humans pairs of summaries and asked them to choose which one was better. This comparison approach is powerful because humans are generally better at comparing two options than providing absolute quality judgments. To continue the cooking analogy, if someone makes you two dishes, it’s easier to say which one you like better than to provide the cook with a rating of each dish on a scale of 1 to 10.
The process then involved three key stages:
First, they created an initial dataset using their base language model (GPT-3) to generate multiple summary variations for each article. Human labelers compared these summaries, creating a dataset of paired preferences – essentially a collection of "this summary is better than that one" judgments.
Second, they trained a reward model to predict these human preferences. The reward model learned to take two summaries as input and predict which one humans would prefer. This is a clever way to turn subjective human preferences into a mathematical function that can guide the learning process.
The third stage is where it gets particularly interesting. They used reinforcement learning to fine-tune their summarization model using the reward model's predictions. Specifically, they used a technique called Proximal Policy Optimization (PPO). In this process, the model generates summaries, the reward model evaluates them, and the model is updated to make summaries that receive higher reward predictions more likely in the future.
Understanding the Building Blocks: How PPO Makes Learning Safe
PPO is important because it is trying to solve a fundamental challenge in reinforcement learning: how do you improve a model's behavior gradually and safely? Switching analogies here, but imagine teaching someone to write - you want them to improve, but if you push for too many changes at once, they might develop bad habits or lose the skills they already have.
The "Proximal" in PPO refers to keeping new behaviors close (proximal) to old ones. To understand it, we first need to understand what we're optimizing. The model (called the "policy") takes in an article and outputs a probability distribution over possible next words when generating a summary. The reward model tells us how good a completed summary is according to predicted human preferences.
Now, when we use PPO to update the model, it follows these steps:
The current model generates several summaries for an article.
The reward model evaluates these summaries.
PPO calculates how to adjust the model's behavior to make better summaries more likely.
Then - and here's the most important part - PPO includes a constraint that limits how much the model can change from its current behavior.
This constraint is implemented through what's called the "clipped objective function." Imagine you have a summary that got a good reward. You want to make similar summaries more likely, but not by too much. PPO puts a limit on how much it can increase or decrease the probability of any behavior, typically around 20% per update. Why is this clipping so important? Without it, the model might make dramatic changes that look good according to the reward model but actually produce worse summaries, forget other useful behaviors it had learned, or find ways to "hack" the reward model by generating strange outputs that get high rewards but aren't actually good summaries.
A technical but important detail is that PPO uses an advantage estimate - it doesn't just look at absolute rewards, but at how much better or worse each summary is compared to what the model typically produces. This helps the model focus on genuine improvements rather than random variations in reward.
This early work revealed both the promise and challenges of scaling human feedback. What the researchers found was interesting: even when they had a reward model that was very good at predicting human preferences, the process of actually getting the language model to generate better summaries was still challenging, even with PPO in place. It was like having a highly refined palate but struggling to translate that taste into cooking skill. (Back to cooking! I swear I have more analogies in the bag.) This insight pointed to a fundamental challenge in AI alignment: knowing what humans want isn't the same as being able to deliver it.
Paper:
The Challenge of Scale: When Bigger Isn't Always Better
But once RLHF showed promise for smaller tasks like summarization, the natural question became: how would it perform at scale? Let’s rewind a bit to a paper from earlier that year, "Scaling Laws for Neural Language Models", that was published by the same research lab. It’s a landmark study because it gave us a mathematical understanding of how language models improve with scale. In it, the researchers showed how model performance improved with size – but also revealed diminishing returns. You couldn't just make models bigger and expect proportionally better results.
To be specific, they discovered that model performance (measured by test loss) follows a power-law relationship with three key factors: model size (number of parameters), dataset size, and compute budget. But what's particularly fascinating is how these factors interact.
[A quick note about test loss: you’ve probably heard the phrase or idea that LLMs are ‘next token predictors’. Test loss just measures how good a model is at predicting the next token. The loss function in this paper is cross-entropy loss, which measures the difference between the model’s predicted probabilities and the perfect predictions.]
Focusing first on model size, the researchers found that making models bigger does consistently improve performance, but each doubling of model size gives you less and less benefit. Mathematically, they found that loss decreases as a power law with model size - specifically, loss
, where N is the number of parameters. This means that to get the same amount of improvement in performance, you need to increase the model size by an exponentially larger amount each time.
Think of it like building a tower. At first, adding more blocks (parameters) makes the tower noticeably taller. But as the tower gets bigger, you need to add more and more blocks to achieve the same increase in height. Eventually, you might need to double the number of blocks just to gain a tiny bit more height.

They also discovered that this diminishing returns curve isn't fixed. It actually depends on whether you have enough training data and compute power to effectively use those additional parameters. If you increase model size without proportionally increasing the amount of training data and compute, you hit diminishing returns much faster. It's like having all those blocks for your tower but not enough time or space to properly place them.
They derived specific formulas for these relationships:
If you want to optimally scale your model, you should increase your dataset size roughly linearly with model size
Compute requirements should increase even faster - approximately with the square of the model size
This explains why simply making bigger models isn't enough - you need to carefully balance all three factors to achieve optimal performance. It's a three-way trade-off between parameters, data, and compute.
Okay, okay. We all have heard about scale with LLMs. So, how does this all relate to RLHF? When researchers started applying RLHF, they discovered that the scaling law relationships became even more complex. Why?
In traditional language model training, we're just trying to predict the next token. But with RLHF, we're trying to do something more sophisticated - we're trying to get the model to generate text that humans will prefer. This involves three different components that each need to scale: the base language model, the reward model, and the RLHF training process itself.
What’s tricky about it is the fact that these components don't necessarily follow the same scaling laws. The reward model, for instance, often needs to be quite large to effectively judge the quality of outputs - but making it too large relative to the base model can lead to instability in training. Have you ever read an incredibly harsh review of a popcorn movie by an esteemed film critic? This is a little like that - if you have a critic who's more sophisticated than the artist they're trying to guide and the critic's standards are too complex for the artist to understand and implement, the feedback becomes less useful.
This insight led to an important practice in RLHF: researchers typically make the reward model smaller than the base model, but still large enough to make meaningful judgments. This creates a sort of sweet spot - the reward model needs to be sophisticated enough to capture human preferences accurately, but not so complex that it makes the training process unstable.
Another fascinating discovery was that the compute requirements for RLHF scale differently than regular language model training. The PPO process we discussed earlier requires generating multiple variations of responses and evaluating them with the reward model. As models get larger, this process becomes computationally expensive very quickly - even more so than the square relationship we saw in the original scaling laws.
Paper:
Scaling RLHF: The InstructGPT Breakthrough
So now we have an interesting puzzle: the scaling laws showed us that bigger models need exponentially more resources to improve, and RLHF adds even more complexity with its three-part training process. How could researchers make this work at scale without running into computational barriers or training instabilities? The answer came through careful experimentation and architectural innovation. OpenAI's paper (OpenAI were really cooking at this time) “Training Language Models to Follow Instructions with Human Feedback” (or the InstructGPT paper, as its more commonly known) showed how to thread this needle, creating systems that were both powerful and aligned with human values. The researchers developed techniques to maintain training stability even with very large models, similar to how José Andrés can scale up recipes to feed hundreds of people in his charity work while still preserving the crucial balance of flavors.
The first technique was introducing an innovation in how they collected human feedback. Instead of just asking humans to compare model outputs directly (as in the summarization paper), they created detailed rubrics for evaluators. These rubrics helped ensure consistency in how different human evaluators judged model outputs, which became increasingly important as they scaled up the amount of feedback needed.
They also developed what they called "preference modeling" - a more sophisticated version of the reward modeling approach. Rather than training a reward model to predict a simple binary preference, they trained it to predict more nuanced human judgments across multiple criteria like helpfulness, truthfulness, and harmlessness. This created a more informative training signal for the model.
But perhaps their most important innovation was in how they handled the PPO training process at scale. They discovered that naive application of PPO to large language models could lead to what they called "policy collapse" - where the model would suddenly start generating very poor outputs. This happened because the optimization process could sometimes find ways to maximize the reward that didn't align with actual human preferences. Or put in another way, if you focus too much on maximizing the reward, the model can start to lose its general language capabilities. If you teach someone to cook only delicious hamburgers - they might get very good at that specific task but lose their ability to cook lasagna or make a sandwich.
To prevent this, they developed a technique called "PPO-ptx" (PPO with pretraining mixture). It works by combining two objectives during training:
The reward maximization objective from standard PPO, which encourages the model to generate outputs that the reward model will score highly.
The original language modeling objective, which involves predicting the next token in a sequence of text.
The key innovation is in how these objectives are balanced. During each training step, the model processes two types of data:
Prompted sequences where it tries to generate helpful responses (optimized using the reward model).
Regular text sequences where it just tries to predict the next token (like its original pretraining).
The researchers found that maintaining this dual training was necessary for stability. If the model spent too much time optimizing for rewards, it would start to generate repetitive or unnatural text. If it spent too much time on language modeling, it wouldn't learn to be helpful enough. To finally switch analogies, you can think of it like teaching someone to become a technical writer. You want them to learn to write clear, precise documentation (the reward optimization), but you also want them to maintain their general writing abilities (the language modeling). PPO-ptx achieves this by alternating between focused practice on technical writing and general writing exercises.
Bringing this together with the scaling conversation, what made this approach particularly powerful was how it scaled with model size. Larger models have more capacity to maintain both their general language abilities and their specialized helpful behaviors. The PPO-ptx process helped them take advantage of this capacity without falling into the traps that pure reward optimization might create.
One final technique they utilized was the introduction of careful parameter initialization and learning rate schedules. When working with larger models, they found that the initial learning rate needed to be much smaller than what worked for smaller models. They gradually increased it according to a carefully designed schedule, similar to how you might start with simple exercises before attempting more complex ones when learning a new skill.
What made all of these techniques particularly effective was how they worked together. The improved feedback collection made the reward model more reliable, which in turn made the PPO training more stable, which allowed them to scale to larger models without losing control of the training process.
Paper:
The Sycophancy Problem: When Helpfulness Conflicts with Truth
But recent research has challenged some of our assumptions about RLHF. In "Towards Understanding Sycophancy in Language Models," researchers at Anthropic pointed out fundamental limitations in how we gather and apply human feedback. The paper explores one of the challenges with RLHF: models can become "sycophantic," meaning they tend to agree with or defer to user statements even when those statements are incorrect. If you’ve used any of these models very often, you might have noticed this tendency. It’s particularly interesting because it reveals a subtle flaw in how RLHF works.
Think back to how RLHF trains models using human feedback. The process assumes that by learning from human preferences, models will become more helpful and truthful. However, what the researchers discovered is that models can learn to optimize for agreement rather than truthfulness. It's similar to how a student might learn to agree with their teacher to get better grades, rather than developing genuine understanding.

The paper demonstrates this through careful experiments where the researchers show that models trained with RLHF tend to change their answers based on what they think the user wants to hear, rather than maintaining consistent, truthful responses. This "sycophancy" becomes more pronounced as models get larger and more sophisticated at predicting what kinds of responses humans might prefer.
The researchers designed their experiments around a clever core idea: they would present models with statements that contained clear factual errors, then observe how the models responded in different contexts. This allowed them to test whether models would maintain truthful responses or adapt their answers to agree with incorrect user statements.
Their primary experiment involved asking models questions in two different ways:
A direct question (e.g., "What is the capital of France?")
The same question, but preceded by an incorrect statement (e.g., "I believe London is the capital of France. What is the capital of France?")
What they found was revealing. When asked directly, models would typically give correct answers. But when the question was preceded by an incorrect statement, RLHF-trained models showed a concerning tendency to shift their answers to align with the user's incorrect belief. For instance, a model might correctly identify Paris as France's capital in the direct question, but then hedge or even agree that London is the capital when responding to the second format. For a more practical and potentially dangerous example, a model might politely reinforce a user’s conspiratorial belief about a historical event rather than correct it, all to preserve a high approval rating.
To quantify this effect, they developed a "sycophancy score" - essentially measuring how much a model's answers changed when presented with incorrect user beliefs. They found that this score typically increased with model size, suggesting that larger models became more sophisticated at picking up and deferring to user beliefs, even incorrect ones.
The researchers then conducted variation experiments to understand what factors influenced this behavior. They found that:
The effect was stronger when the incorrect statement was presented as a personal belief ("I believe...") rather than as a simple statement.
Models were more likely to become sycophantic about subjective topics than objective facts.
The sycophancy increased when models were explicitly instructed to be helpful and agreeable.
What makes these findings particularly important is how they reveal a fundamental tension in RLHF training. The process of optimizing for human preferences can inadvertently create a pressure for models to agree with humans rather than maintain truthful responses. This happens because human feedback often rewards polite, agreeable responses, even though we ultimately want models that will truthfully correct misconceptions.
Paper:
Finding a Better Way: Direct Preference Optimization
These challenges have spurred innovation. A particularly exciting development emerged in late 2023 with "Direct Preference Optimization" (DPO). This approach showed that language models themselves could serve as reward models, eliminating the need for a separate reward model entirely. It's like realizing that instead of needing a food critic to improve your cooking, you could develop a more refined palate yourself. (And he brings it back full circle.) DPO not only simplified the training process but also improved performance and reduced computational requirements.
Remember how traditional RLHF requires three components: the base model, a reward model, and the PPO training process. While this works, it's computationally expensive and can lead to issues like the sycophancy we just discussed. DPO takes a fundamentally different approach by reconceptualizing how we can learn from human preferences.
The key insight of DPO is that we can transform the problem of learning from preferences into a form of supervised learning. Instead of training a separate reward model and then using PPO to optimize the base model, DPO directly updates the model's parameters to make preferred outputs more likely and non-preferred outputs less likely.
To understand how this works, let's break it down by steps. In traditional RLHF, if humans prefer response A over response B, we would:
Train a reward model to predict this preference.
Use PPO to gradually adjust the model to generate more A-like responses.
Carefully balance this optimization with the original language modeling objective (like in PPO-ptx).
DPO instead derives a mathematical relationship that shows how we can directly adjust the model's parameters to reflect these preferences. It's like finding a shortcut in a maze – instead of carefully exploring many possible paths (PPO), we've found a direct route to our destination.
What makes this particularly elegant is that it eliminates the need for the separate reward model entirely. The researchers showed that the language model itself implicitly contains the information needed to learn from preferences. Think about it this way: a language model already knows how to assign probabilities to different possible responses. DPO simply adjusts these probabilities to align with human preferences.
This approach has several important advantages:
It's more computationally efficient since we don't need a separate reward model or complex PPO training.
It's more stable because we're not balancing multiple competing objectives.
It might be less prone to sycophancy because it's learning a more direct relationship between input and preferred output.
The approach might be less prone to sycophancy because it's learning a more direct relationship between input and preferred output. Unlike traditional RLHF, where the reward model might learn to favor agreeable responses over truthful ones, DPO's direct optimization approach means the model learns to align its output probabilities with human preferences without the intermediary reward model that could inadvertently encourage people-pleasing behavior. Because DPO doesn’t rely on a specialized reward function that might accidentally reward ‘pleasing the user,’ it can directly adjust probabilities based on user preference data without introducing that extra source of potential reward exploitation. This more direct learning process could help maintain the model's commitment to truthfulness while still incorporating human feedback.
The researchers demonstrated that DPO could achieve similar or better results compared to RLHF while being significantly simpler to implement and train. This is particularly important as we think about scaling these systems – simpler training procedures are often more robust when applied to larger models.
Paper:
Wrap-Up
The evolution of RLHF reflects a broader pattern in AI development: initial breakthroughs often reveal new challenges, which in turn drive innovation. As we've scaled these systems, we've learned that effective alignment isn't just about gathering more human feedback or building bigger models – it's about finding more efficient and reliable ways to translate human preferences into AI behavior.
To finish off this intro series, I’ll cover the open-source revolution, multimodal advances, mixture-of-experts (particularly en vogue right now with the DeepSeek releases) and other architectural innovations, generative agents (also en vogue, particularly with OpenAI’s Operator release), and finish up with some discussion around Constitutional AI and alignment advances.
Hopefully this shed some light on a concept that is extremely important to the progress in this field. If there is anything specific you’d like to me write about because you think it’s important and just don’t quite understand it, I’m happy to hear from you.